Single multi-omic dataset (EB)
[1]:
import numpy as np
import scanpy as sc
import scvelo as scv
import torch
import matplotlib.pyplot as plt
import umap
import os
import multivelovae as vv
from datetime import datetime
[2]:
torch.cuda.is_available()
[2]:
True
[3]:
now = datetime.now()
date = now.strftime("%m_%d_%Y")
Read in processed data and define places to store output
[4]:
dataset = "8964-KL-1"
adata = sc.read_h5ad('8964-KL-1_adata_postpro.h5ad')
adata_atac = sc.read_h5ad('8964-KL-1_adata_atac_postpro.h5ad')
[5]:
model_path_base = f"checkpoints/{dataset}"
figure_path_base = f"figures/{dataset}"
data_path_base = f"data/{dataset}"
[6]:
gene_plot = ['NANOG', 'ESRG', 'DPPA4', 'GRID2', 'TPBG', 'PAX6', 'ENC1', 'SAT1']
np.all(np.isin(gene_plot, adata.var_names))
[6]:
True
[7]:
adata_atac.layers['Mc'] = adata_atac.layers['Mc'].A
[8]:
adata, adata_atac
[8]:
(AnnData object with n_obs × n_vars = 4240 × 3138
obs: 'total_unspliced', 'total_spliced', 'log1p_total_unspliced', 'log1p_total_spliced', 'fraction_u', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_20_genes', 'total_counts_mt', 'log1p_total_counts_mt', 'pct_counts_mt', 'total_counts_rb', 'log1p_total_counts_rb', 'pct_counts_rb', 'total_counts_hla', 'log1p_total_counts_hla', 'pct_counts_hla', 'total_counts_hb', 'log1p_total_counts_hb', 'pct_counts_hb', 'outlier', 'initial_size_unspliced', 'initial_size_spliced', 'initial_size', 'n_counts', 'S_score', 'G2M_score', 'phase', 'CC_difference', 'total_unspliced2', 'total_spliced2', 'log1p_total_unspliced2', 'log1p_total_spliced2', 'fraction_u2', 'n_c', 'n_Mu', 'n_Ms', 'leiden'
var: 'gene_ids', 'feature_types', 'n_cells', 'mt', 'rb', 'hla', 'hb', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'gene_count_corr', 'highly_variable', 'mean', 'std'
uns: 'leiden', 'leiden_colors', 'log1p', 'neighbors', 'pca', 'rank_genes_groups', 'umap'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
layers: 'Ms', 'Mu', 'spliced', 'unspliced'
obsp: 'connectivities', 'distances',
AnnData object with n_obs × n_vars = 4240 × 3138
obs: 'n_counts', 'leiden'
layers: 'Mc'
obsp: 'connectivities')
[9]:
os.makedirs(figure_path_base, exist_ok=True)
scv.pl.scatter(adata, basis='umap', color='leiden')
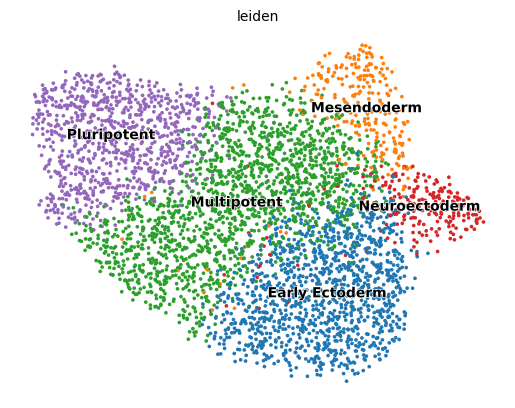
[10]:
# Phase portraits of original data
scv.pl.scatter(adata, basis=gene_plot, color='leiden')

[11]:
figure_path = figure_path_base+'/'+date
model_path = model_path_base+'/'+date
data_path = data_path_base
Initialize and train a MultiVeloVAE
[12]:
key = 'vae'
[13]:
torch.manual_seed(2022)
np.random.seed(2022)
model = vv.VAEChrom(adata,
adata_atac,
device='cuda:0',
plot_init=False,
gene_plot=gene_plot,
cluster_key="leiden",
figure_path=figure_path,
embed="umap")
model.train(plot=False,
gene_plot=gene_plot,
figure_path=figure_path,
embed="umap"
)
model.save_model(model_path)
model.save_anndata(data_path, file_name="out.h5ad")
Latent dimension set to 16.
Learning rate set to 9.1e-4 based on data sparsity.
Early stop threshold set to 1.6.
Using Gaussian Prior.
Initializing using the steady-state and dynamical models.
2613 out of 3138 = 83.3% genes have good ellipse fits.
KS-test result: [1. 1. 1. 1. 1. 1. 1.]
Assigning cluster 6 to repressive.
Initial induction: 2532, repression: 606 out of 3138.
-------------------------- Train a MultiVeloVAE -------------------------
********* Creating Training and Validation Datasets *********
Total Number of Iterations Per Epoch: 12, test iteration: 22
********* Finished. *********
********* Stage 1 *********
Epoch 1: Train ELBO = -21489.391, Test ELBO = -250868.052 Total Time = 0 h : 0 m : 0 s
Epoch 50: Train ELBO = 14445.737, Test ELBO = 14370.251 Total Time = 0 h : 0 m : 7 s
Epoch 100: Train ELBO = 16401.478, Test ELBO = 16270.854 Total Time = 0 h : 0 m : 15 s
Epoch 150: Train ELBO = 16905.745, Test ELBO = 16748.806 Total Time = 0 h : 0 m : 22 s
Epoch 200: Train ELBO = 17068.374, Test ELBO = 16926.925 Total Time = 0 h : 0 m : 29 s
Epoch 250: Train ELBO = 17170.108, Test ELBO = 17017.487 Total Time = 0 h : 0 m : 36 s
Epoch 300: Train ELBO = 17220.520, Test ELBO = 17036.000 Total Time = 0 h : 0 m : 44 s
Epoch 350: Train ELBO = 17260.815, Test ELBO = 17087.239 Total Time = 0 h : 0 m : 51 s
Epoch 400: Train ELBO = 17289.872, Test ELBO = 17104.871 Total Time = 0 h : 0 m : 58 s
Epoch 450: Train ELBO = 17318.591, Test ELBO = 17122.996 Total Time = 0 h : 1 m : 6 s
Epoch 500: Train ELBO = 17335.009, Test ELBO = 17131.167 Total Time = 0 h : 1 m : 13 s
Epoch 550: Train ELBO = 17353.692, Test ELBO = 17138.741 Total Time = 0 h : 1 m : 20 s
Epoch 600: Train ELBO = 17363.631, Test ELBO = 17144.883 Total Time = 0 h : 1 m : 28 s
Epoch 650: Train ELBO = 17378.854, Test ELBO = 17153.178 Total Time = 0 h : 1 m : 35 s
********* Stage 1: Early Stop Triggered at epoch 655. *********
********* Retrieving best model from iteration 7723. *********
********* Stage 2 *********
Cell-wise KNN estimation.
Using 148 latent neighbors to select ancestors.
Percentage of Invalid Sets: 0.004
Average Set Size: 17
Finished. Actual Time: 0 h : 0 m : 3 s
********* Velocity Refinement Round 1 *********
Epoch 678: Train ELBO = 17250.644, Test ELBO = 17073.383 Total Time = 0 h : 1 m : 42 s
********* Round 1: Early Stop Triggered at epoch 678. *********
********* Retrieving best model from iteration 8120. *********
Cell-wise KNN estimation.
Finished. Actual Time: 0 h : 0 m : 0 s
********* Velocity Refinement Round 2 *********
Epoch 694: Train ELBO = 17221.109, Test ELBO = 17035.956 Total Time = 0 h : 1 m : 46 s
********* Round 2: Early Stop Triggered at epoch 694. *********
********* Retrieving best model from iteration 8307. *********
Change in x0: 0.110
Cell-wise KNN estimation.
Finished. Actual Time: 0 h : 0 m : 0 s
********* Velocity Refinement Round 3 *********
Epoch 706: Train ELBO = 17217.978, Test ELBO = 17019.916 Total Time = 0 h : 1 m : 49 s
********* Round 3: Early Stop Triggered at epoch 706. *********
********* Retrieving best model from iteration 8450. *********
Change in x0: 0.069
********* Stage 2: Early Stop Triggered at round 3. *********
Final: Train ELBO = 17217.978, Test ELBO = 17019.916
********* Finished. Total Time = 0 h : 1 m : 49 s *********
Computing velocity.
Selected 648 velocity genes.
Writing anndata output to file.
Downstream analyses
[14]:
std_z = adata.obsm[f"{key}_std_z"]
z = adata.obsm[f"{key}_z"]
[15]:
# UMAP embedding from latent cell space
umap_obj = umap.UMAP(n_neighbors=30, n_components=2, min_dist=0.25, random_state=2022)
z_umap = umap_obj.fit_transform(z)
[16]:
adata.obsm['X_z_umap'] = z_umap
[17]:
# Compute velocity graph and visualize it, together with inferred latent time
vv.model.velocity_graph(adata, key=key)
vv.velocity_embedding_stream(adata, key=key, basis='umap', color='leiden', title="", figsize=(8,6), legend_loc='right margin')
vv.velocity_embedding_stream(adata, key=key, basis='umap', color=f'{key}_time', color_map='gnuplot', title="", figsize=(8,6), legend_loc='right margin')
computing velocity graph (using 1/8 cores)
finished (0:00:09) --> added
'vae_velocity_norm_graph', sparse matrix with cosine correlations (adata.uns)
computing velocity embedding
finished (0:00:00) --> added
'vae_velocity_norm_umap', embedded velocity vectors (adata.obsm)


[18]:
# Show Z UMAP
vv.velocity_embedding_stream(adata, key=key, basis='z_umap', color='leiden', title="", figsize=(8,6), legend_loc='right margin')
vv.velocity_embedding_stream(adata, key=key, basis='z_umap', color=f'{key}_time', color_map='gnuplot', title="", figsize=(8,6), legend_loc='right margin')
computing velocity embedding
finished (0:00:00) --> added
'vae_velocity_norm_z_umap', embedded velocity vectors (adata.obsm)


[19]:
# Dynamic plots of modality level by latent time for genes of interest
vv.dynamic_plot(adata, adata_atac, gene_plot, key=key, color_by='leiden')
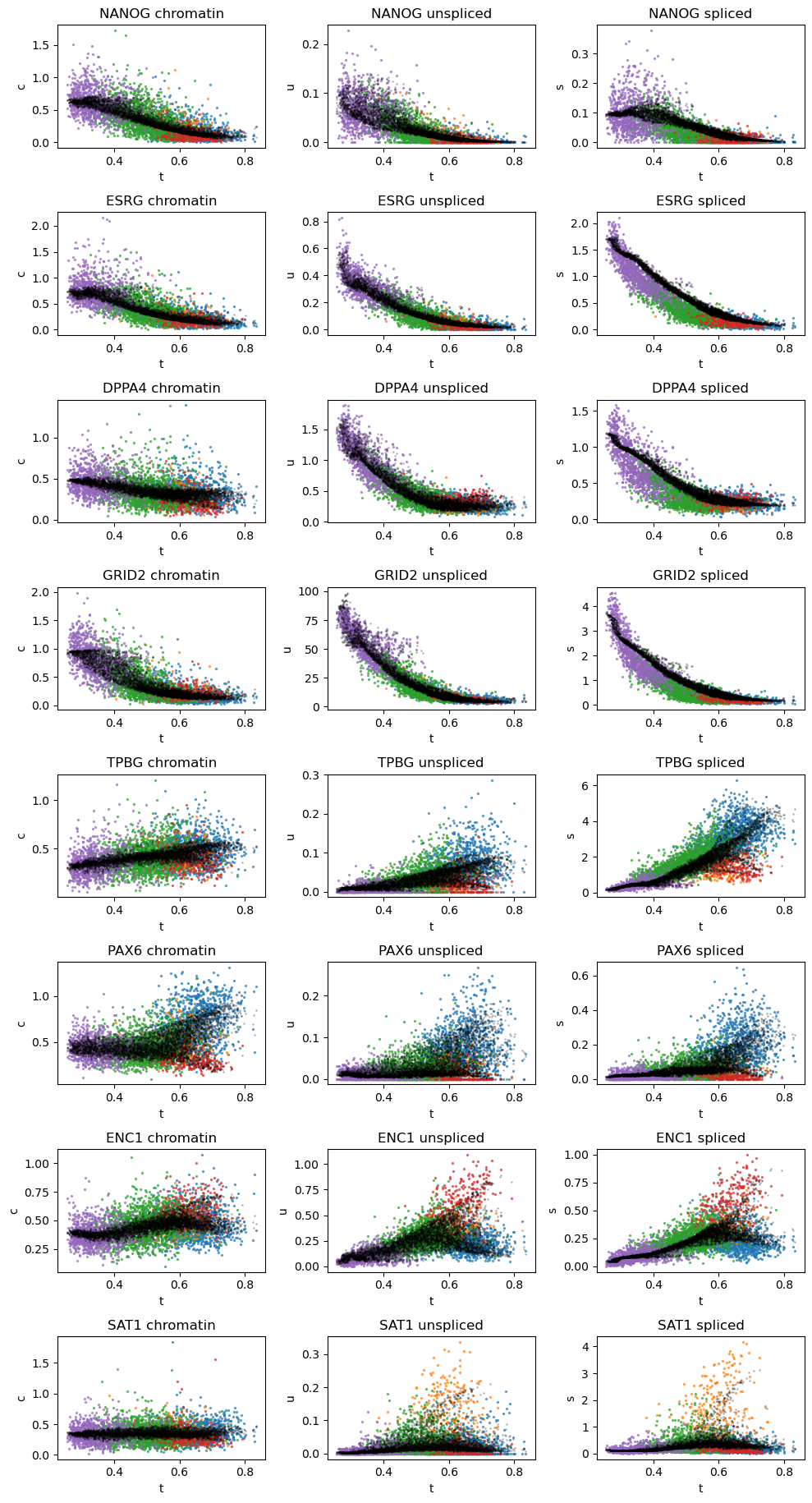
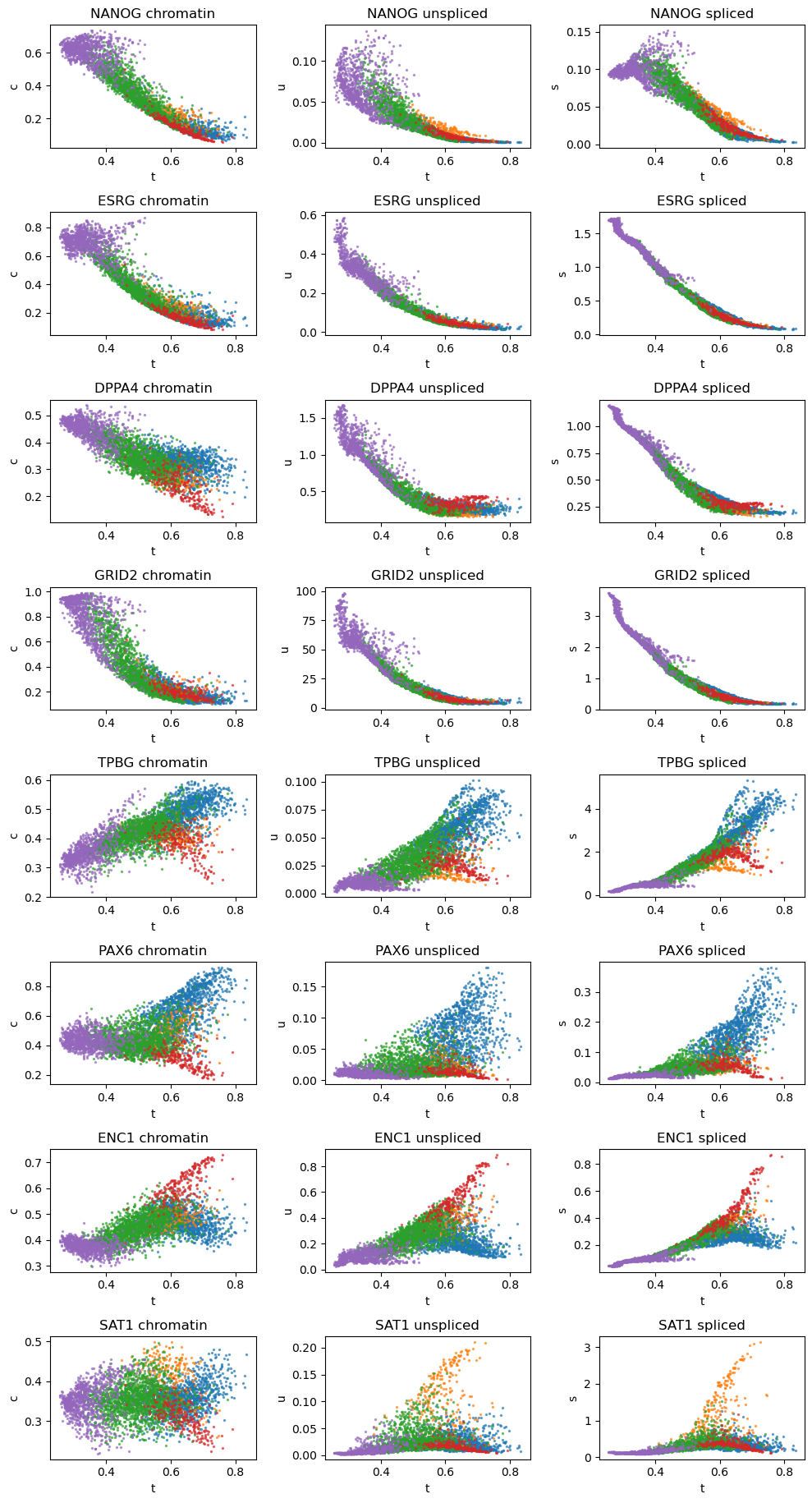
[20]:
# Dynamic plots of reconstructed values only
vv.dynamic_plot(adata, adata_atac, gene_plot, key=key, color_by='leiden', show_pred_only=True)
Differential velocity test
[21]:
adata.layers['velocity_normalized'] = adata.layers[f'{key}_velocity'] / np.max(np.abs(adata.layers[f'{key}_velocity']), axis=0)
Between Early Ectoderm and other lineages
[22]:
a = np.isin(adata.obs['leiden'], ['Early Ectoderm'])
b = np.isin(adata.obs['leiden'], ['Mesendoderm', 'Neuroectoderm'])
[23]:
df_dd_ = vv.model.differential_dynamics(adata, adata_atac, model=model, idx1=a, idx2=b, mode='change')
[24]:
import matplotlib.colors as mcolors
[ ]:
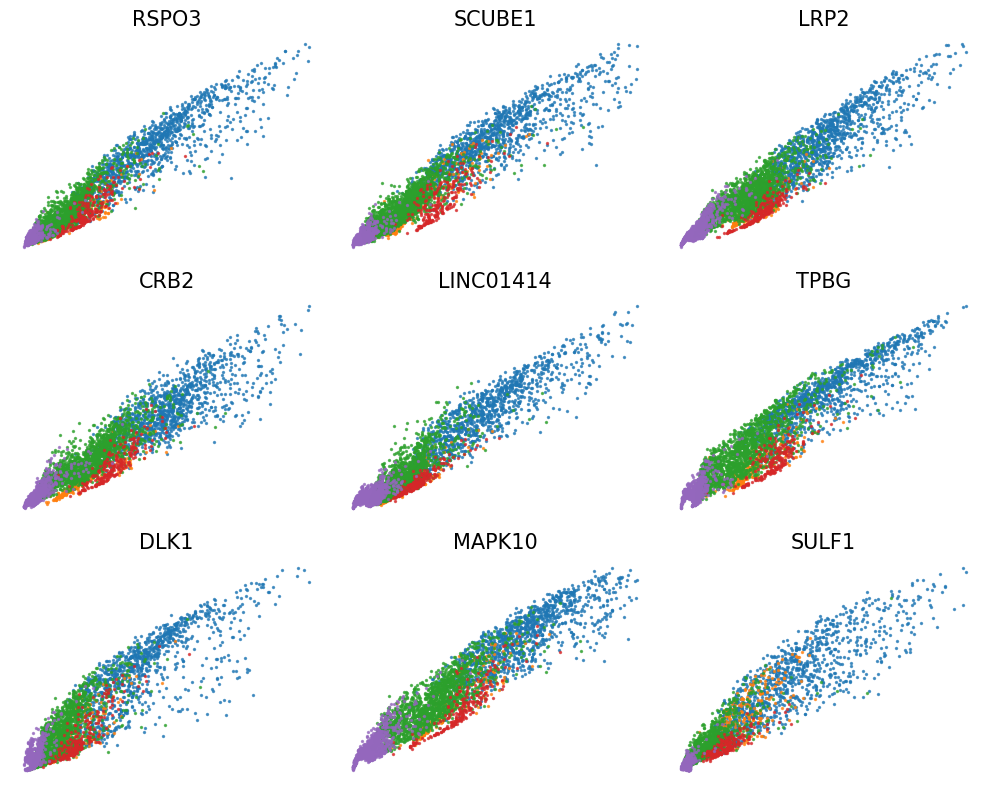
genes = df_dd_.sort_values(by=['bayes_factor_v', 'log2_diff_v'], ascending=[False, False])[df_dd_['log2_diff_v']>0].index[:9]
scv.pl.scatter(adata, basis='umap', layer='velocity_normalized', color=genes, title=[x+' velocity' for x in genes], frameon=False, ncols=3, colorbar=False, wspace=0.1, hspace=0.1,
fontsize=30, color_map='coolwarm', norm=mcolors.CenteredNorm(halfrange=1))
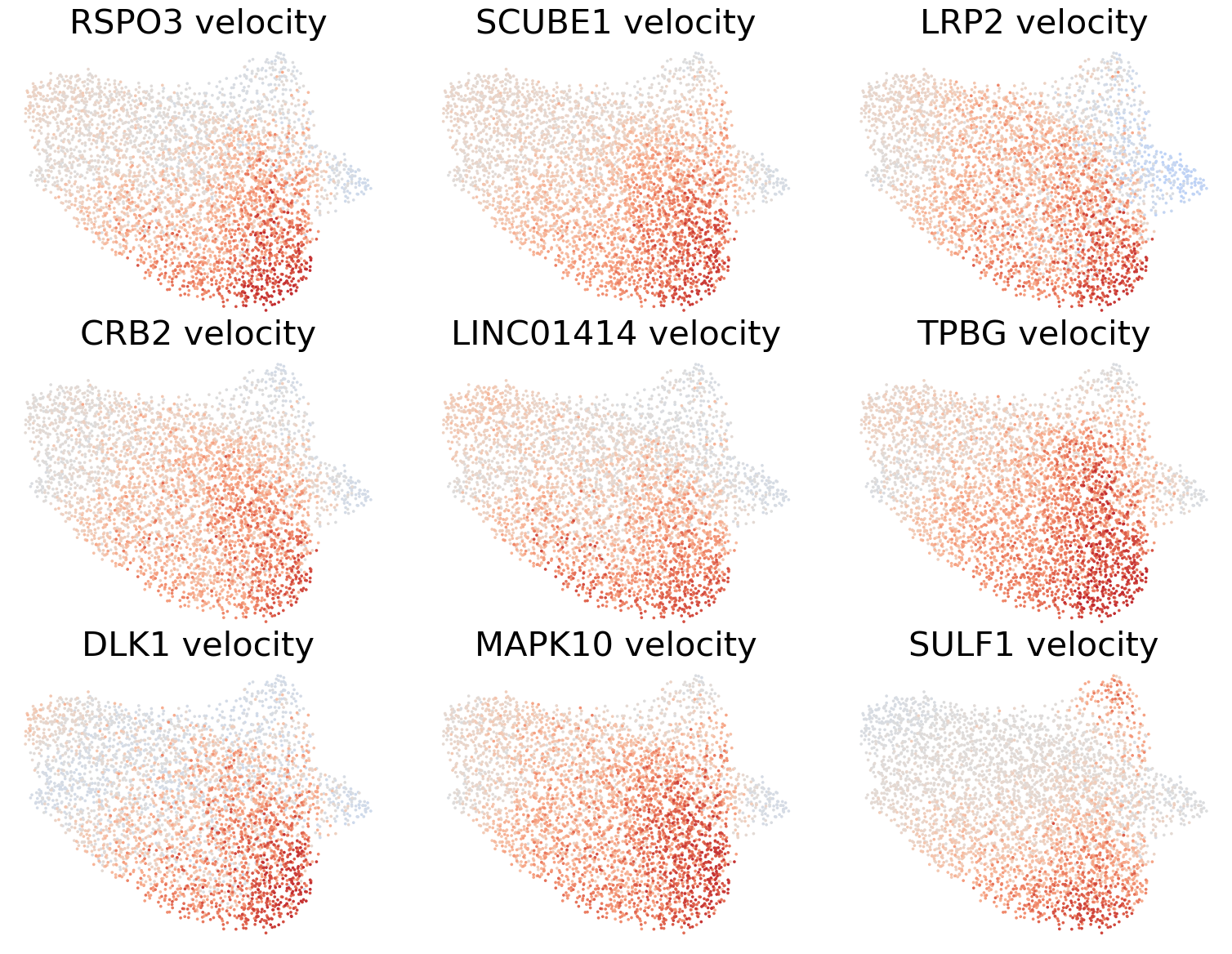
[26]:
vv.scatter_plot(adata, adata_atac, genes, color_by='leiden', show_pred_only=True, axis_on=False, frame_on=False, n_cols=3, figsize=(10,8), fontsize=15)
Between Mesendoderm and other lineages
[27]:
a = np.isin(adata.obs['leiden'], ['Mesendoderm'])
b = np.isin(adata.obs['leiden'], ['Early Ectoderm', 'Neuroectoderm'])
[28]:
df_dd_ = vv.model.differential_dynamics(adata, adata_atac, model=model, idx1=a, idx2=b, mode='change')
[ ]:
genes = df_dd_.sort_values(by=['bayes_factor_v', 'log2_diff_v'], ascending=[False, False])[df_dd_['log2_diff_v']>0].index[:9]
scv.pl.scatter(adata, basis='umap', layer='velocity_normalized', color=genes, title=[x+' velocity' for x in genes], frameon=False, ncols=3, colorbar=False, wspace=0.1, hspace=0.1,
fontsize=30, color_map='coolwarm', norm=mcolors.CenteredNorm(halfrange=1))
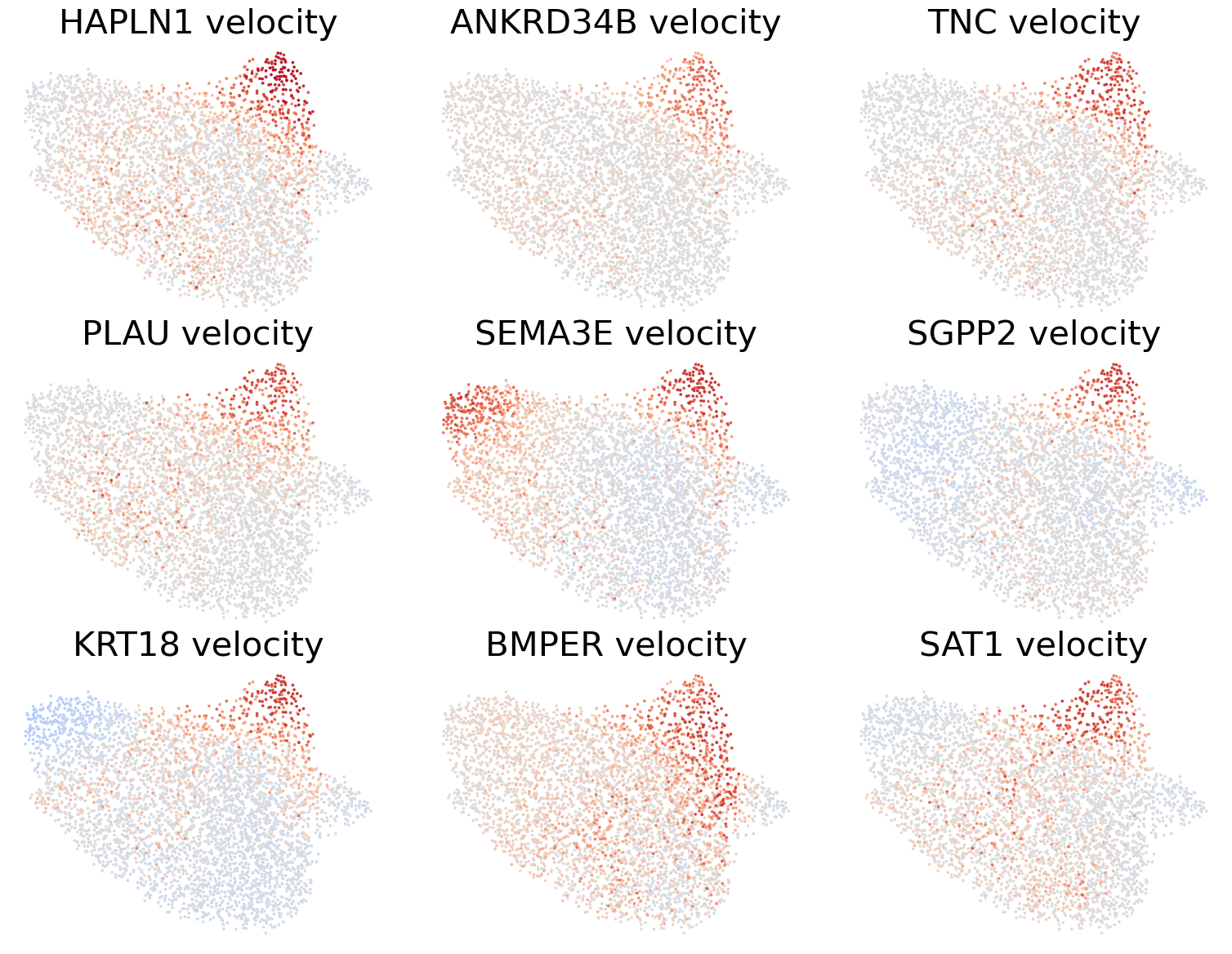
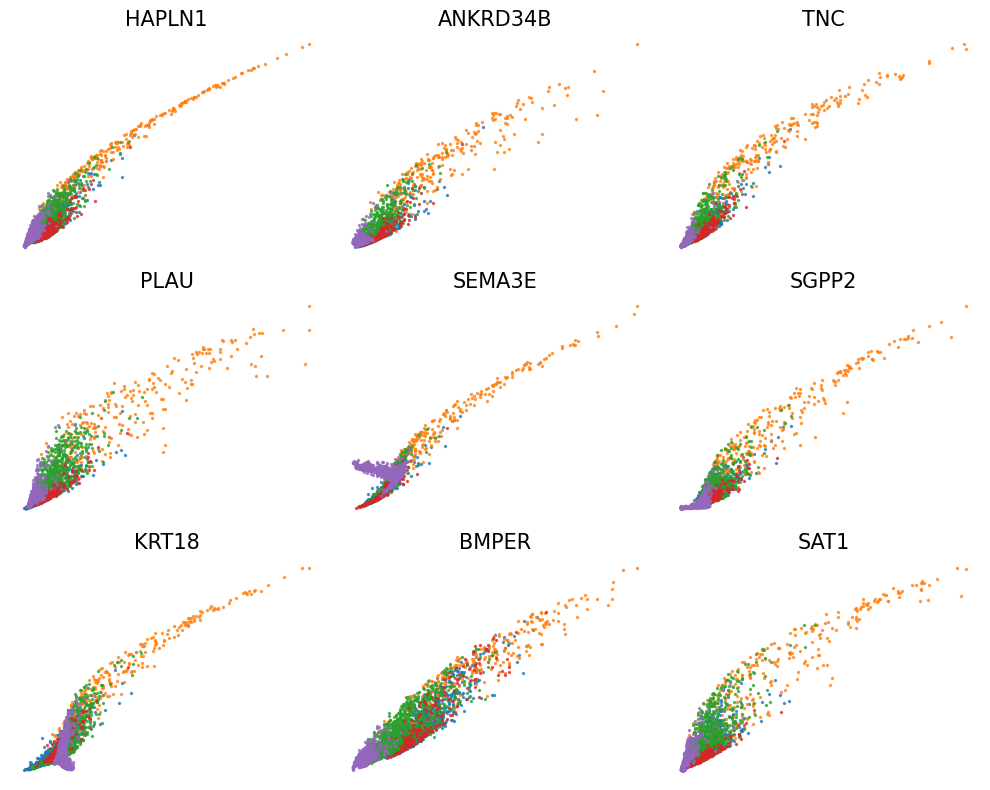
[30]:
vv.scatter_plot(adata, adata_atac, genes, color_by='leiden', show_pred_only=True, axis_on=False, frame_on=False, n_cols=3, figsize=(10,8), fontsize=15)
Between Neuroectoderm and other lineages
[31]:
a = np.isin(adata.obs['leiden'], ['Neuroectoderm'])
b = np.isin(adata.obs['leiden'], ['Mesendoderm', 'Early Ectoderm'])
[32]:
df_dd_ = vv.model.differential_dynamics(adata, adata_atac, model=model, idx1=a, idx2=b, mode='change')
[ ]:
genes = df_dd_.sort_values(by=['bayes_factor_v', 'log2_diff_v'], ascending=[False, False])[df_dd_['log2_diff_v']>0].index[:9]
scv.pl.scatter(adata, basis='umap', layer='velocity_normalized', color=genes, title=[x+' velocity' for x in genes], frameon=False, ncols=3, colorbar=False, wspace=0.1, hspace=0.1,
fontsize=30, color_map='coolwarm', norm=mcolors.CenteredNorm(halfrange=1))
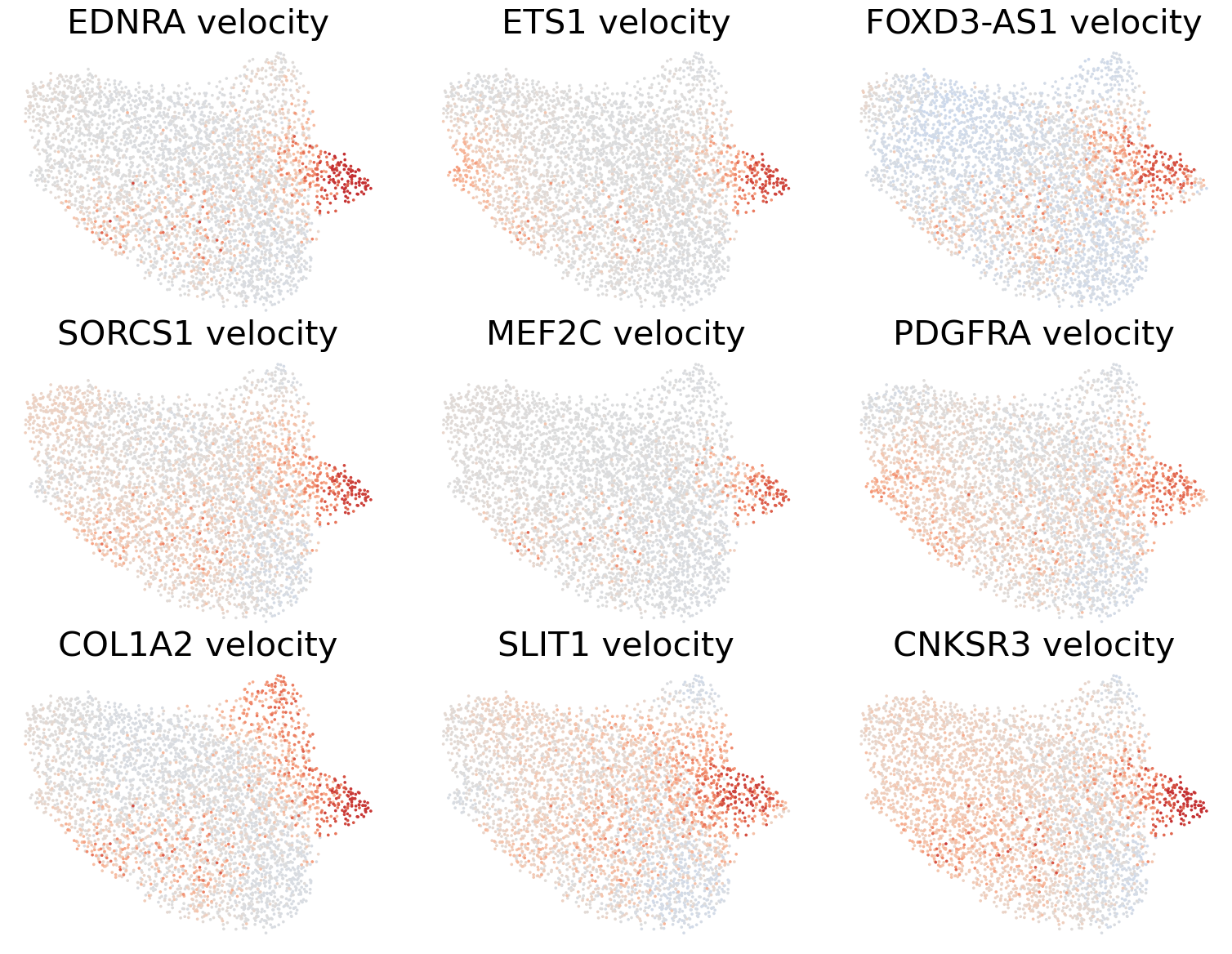
[34]:
vv.scatter_plot(adata, adata_atac, genes, color_by='leiden', show_pred_only=True, axis_on=False, frame_on=False, n_cols=3, figsize=(10,8), fontsize=15)
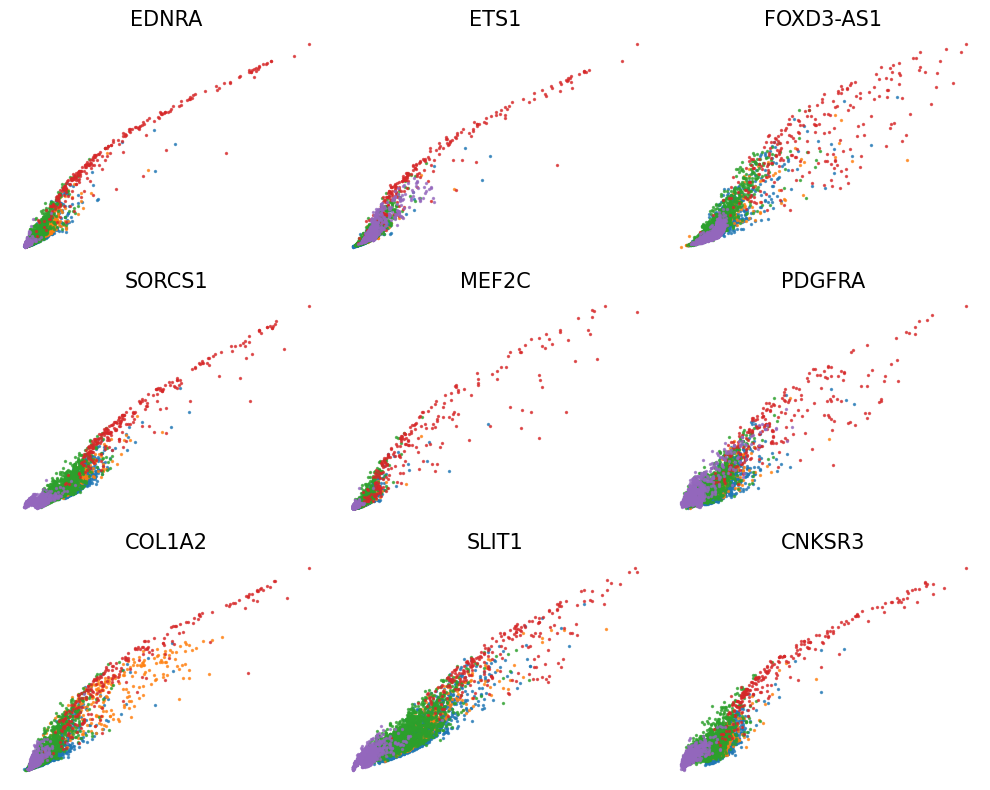
Plot phase portraits of genes with the highest likelihoods
[35]:
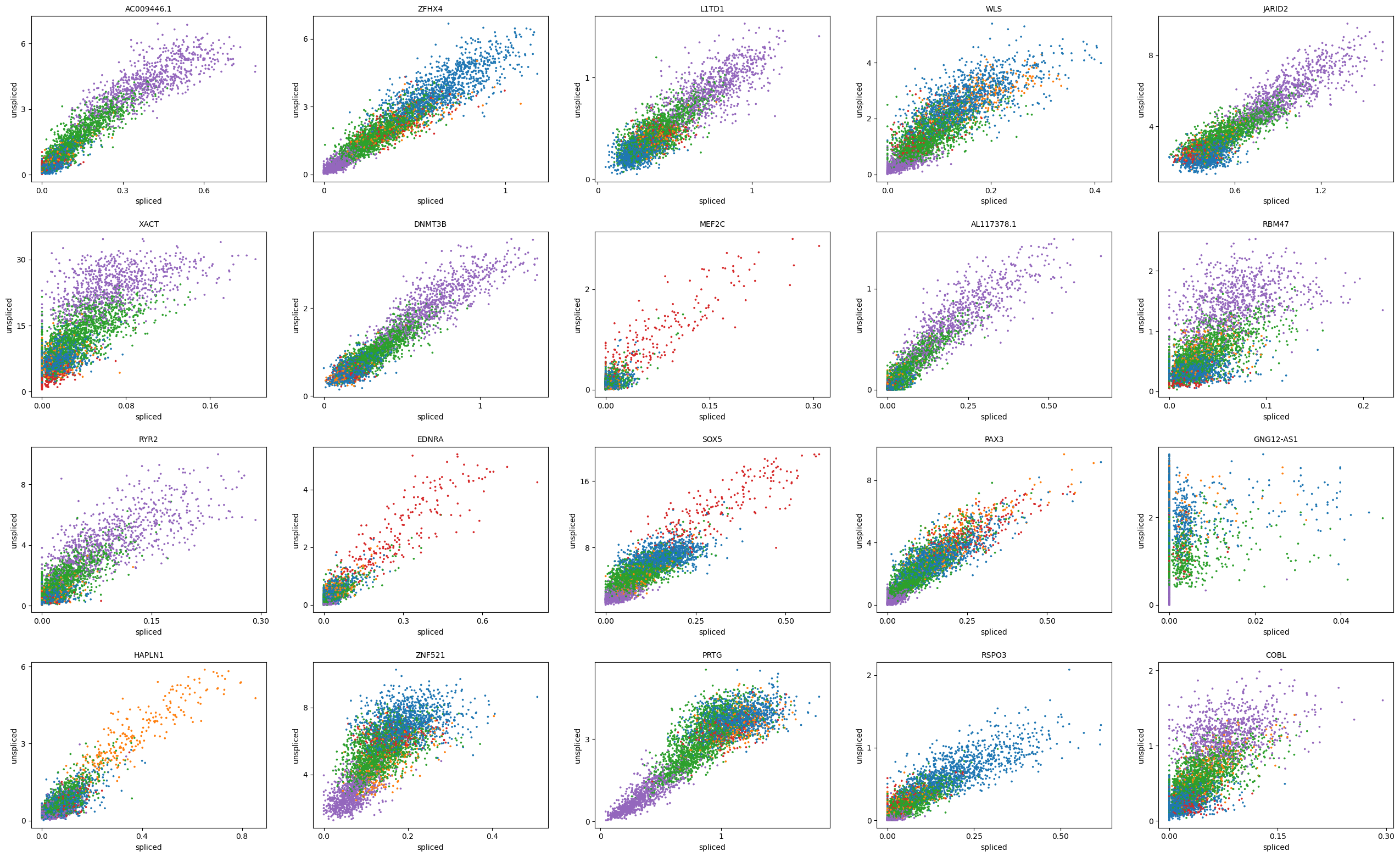
top_genes = adata[:, adata.var[f'{key}_velocity_genes']].var[f'{key}_likelihood'].sort_values(ascending=False).index
[36]:
scv.pl.scatter(adata, basis=top_genes[:20], color='leiden', ncols=5)
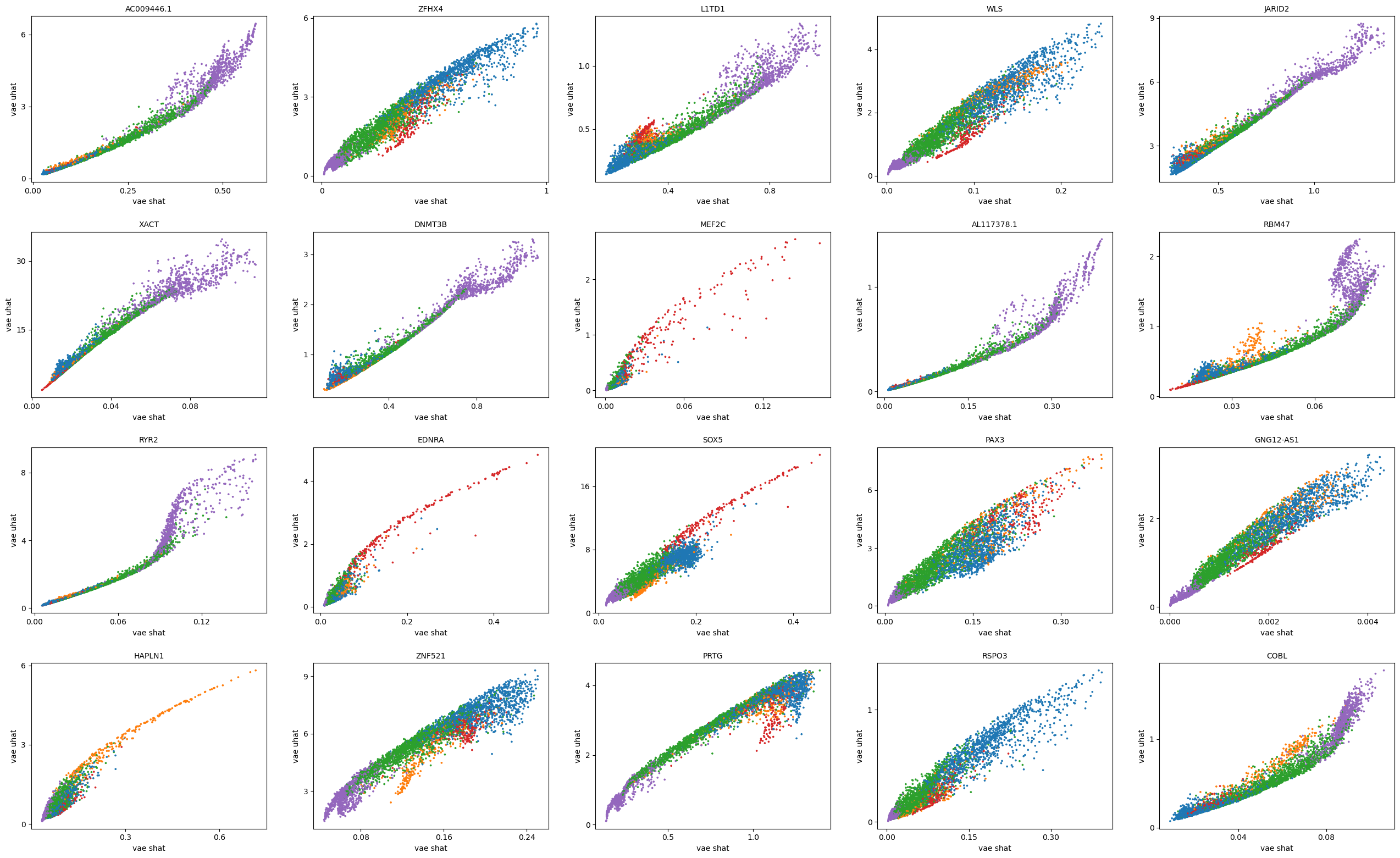
[37]:
scv.pl.scatter(adata, basis=top_genes[:20], x=f'{key}_shat', y=f'{key}_uhat', color='leiden', ncols=5)
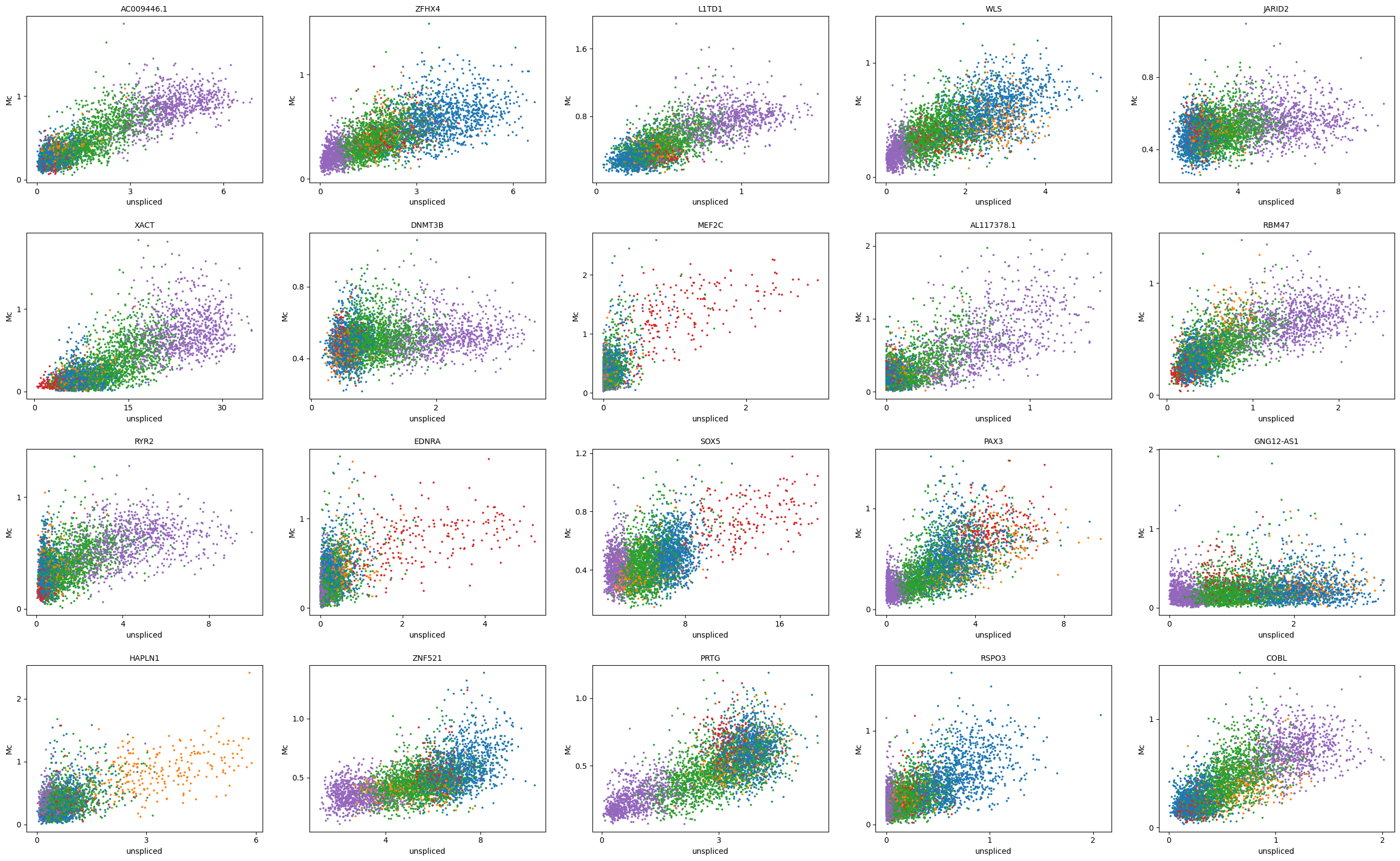
[38]:
adata.layers['Mc'] = adata_atac.layers['Mc'].copy()
[39]:
scv.pl.scatter(adata, x='Mu', y='Mc', basis=top_genes[:20], color='leiden', ncols=5)
[40]:
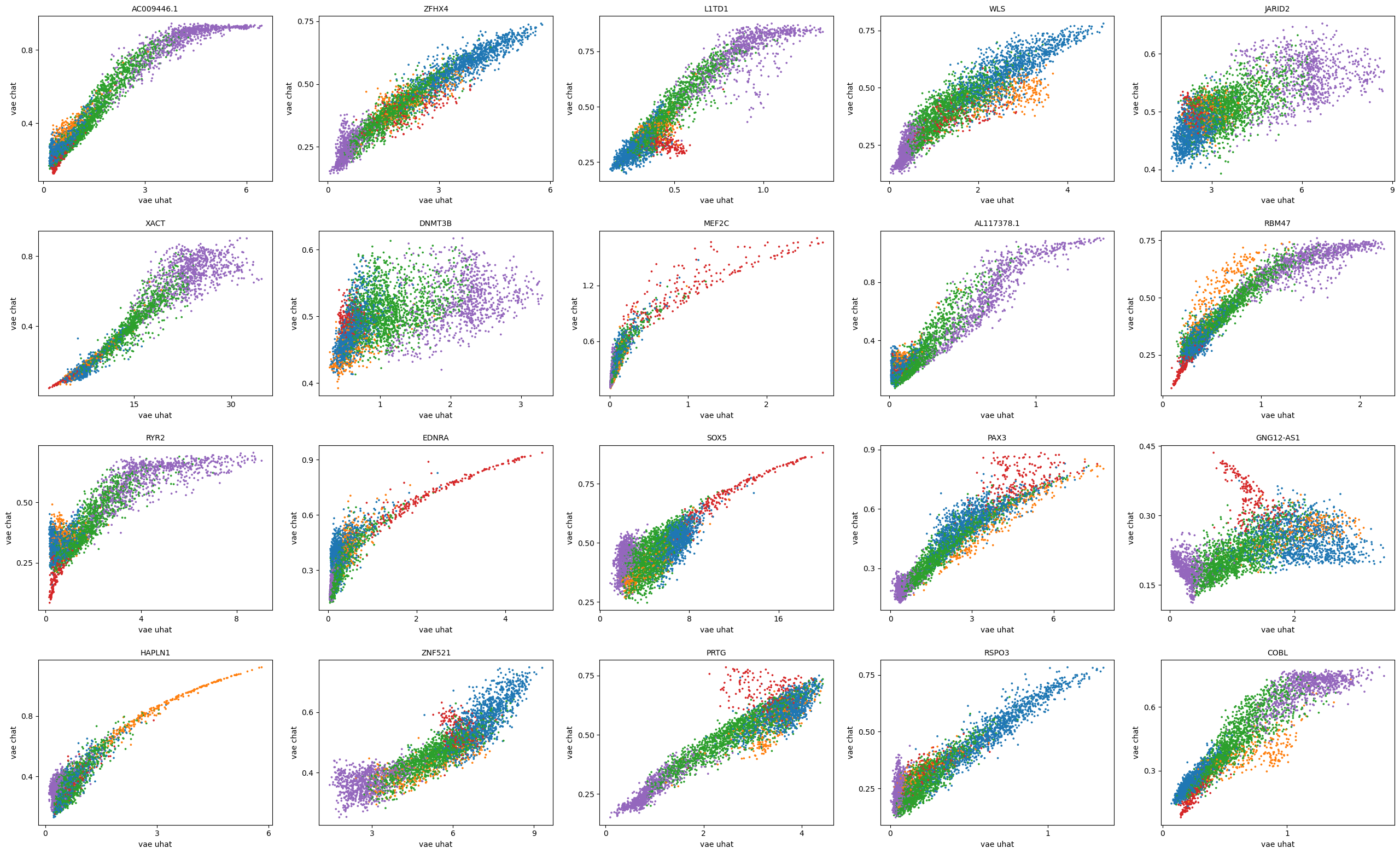
scv.pl.scatter(adata, basis=top_genes[:20], x=f'{key}_uhat', y=f'{key}_chat', color='leiden', ncols=5)
Distributions of inferred rate parameters
[41]:
fig, axs = plt.subplots(1, 6, figsize=(40, 5))
axs[0].hist(adata.var[f'{key}_alpha_c'], bins=100);
axs[1].hist(adata.var[f'{key}_alpha'], bins=100);
axs[2].hist(adata.var[f'{key}_beta'], bins=100);
axs[3].hist(adata.var[f'{key}_gamma'], bins=100);
axs[4].hist(adata.var[f'{key}_scaling_c'], bins=100);
axs[5].hist(adata.var[f'{key}_scaling_u'], bins=100);

Save the final result
[42]:
adata.write_h5ad(data_path_base+"/final.h5ad")
[ ]: